
Marcov Assumption
마르코프 가정: 상태 St+1은 상태 St에 의해서만 결정된다.
즉, 미래를 결정하는 것은 현재뿐이다. 과거는 상관없다.
Marcov Process
마르코프 가정을 만족하는 연속적인 일련의 확률 과정
일련의 상태 <s1, s2, ..., st>와 상태 전이 확률 P로 이루어짐
- MP = (S, P)
- 상태 전이 확률 P_ij = Pr(St+1 = sj | St = si): 상태 i에서 상태 j로 바뀔 확률
*P_ij: P에 아래첨자 i, j
+) Marcov Reward Process
각 상태에서의 보상 측정
마르코프 과정, 보상 R, 감가율 γ(감마)로 이루어짐
- MRP = (S, P, R, γ)
- 상태 집합 S = {s1, s2, ..., s}: MDP에서 가질 수 있는 모든 상태의 집합
- 상태 전이 확률 P_ij = Pr(St+1 = sj | St = si): 상태 i에서 상태 j로 바뀔 확률
- 보상 함수 r(si) = E[Rt+1 | St = si]: 상태 si에서 기대되는 보상 Rt+1(이번 상태-행동에서의 보상은 다음 상태에서 받으므로)
Marcov Decision Process
마르코프 과정을 바탕으로 한 의사 결정 과정
마르코프 과정, 행동 A, 보상 R, 감가율 γ(감마)로 이루어짐
- MDP = (S, A, P, R, γ)
- 상태 집합 S = {s1, s2, ..., s}: MDP에서 가질 수 있는 모든 상태의 집합
- 행동 집합 A = {a1, a2, ..., a}: 행동 주체인 agent가 할 수 있는 모든 행동의 집합
- 상태 전이 확률 P_ss'^a = P(s'|s, a) = P[st+1 = s' | st = s, at = a]: 상태 s에서 행동 a를 취했을 때 상태 s'로 변할 확률
- P_ss'^a: P에 아래첨자 s, s', 위첨자 a
- 보상 함수 R = rt+1 = R(st, at): agent가 상태 st에서 행동 at를 취한 것에 대한 보상(환경이 agent에게 보상 제공)
Return
강화학습은 시행착오를 겪으며 보상을 최대화하는 방향으로 정책을 학습하는 과정. 행동의 좋고 나쁨은 episode에서 받은 보상의 합으로 결정되는데 이것을 return 값 Gt로 정의
Gt = Rt+1 + γ*Rt+2 + γ^2*Rt+3 + ... + γ^(T-t)*R_T+1
감가율 γ: 각 보상에 얼마큼의 가중치를 둘 것인지를 결정. 0과 1 사이의 값으로, γ가 1에 가까울수록 미래에 보상에 많은 가중치를 둠
즉, 강화학습의 목표인 '보상' 최대화에서의 보상은 episode당 보상이 아니라 Return Gt를 말함
Value Function
가치가 높다 == 그 상태의 Return 값에 대한 기댓값이 높다
큰 Return 값을 가지려면 Return 값을 최대화하는 정책을 선택해야 함
상태 가치 함수(state-value function)와 상태-행동 가치 함수(action-value function)으로 나뉨
state-value function

상태 si에서의 상태 가치 함수가 상태 si에서의 Gt(Return 값 == 누적 보상)과 같으므로,

상태 가치 함수 V_pi(s)는 상태 s로부터 가능한 모든 상태-행동 가치 함수 Q_pi(s, a)의 기댓값
action-value function
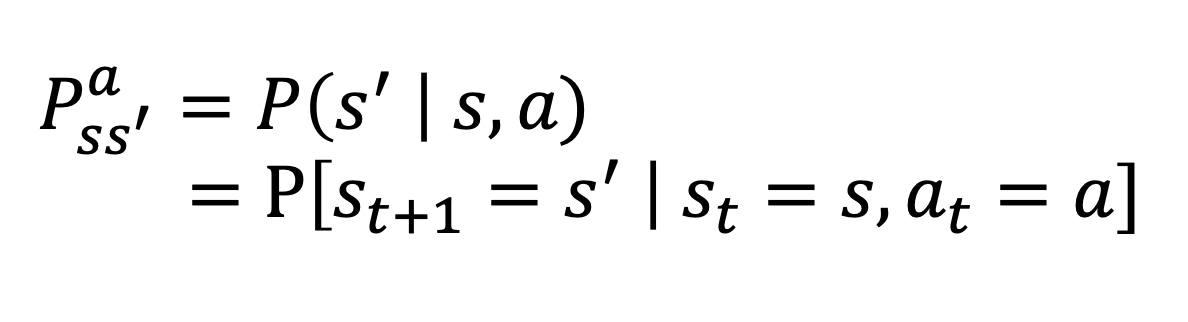
상태 전이 함수 P: 상태 s에서 행동 a를 취했을 때 상태 s'로 변할 확률
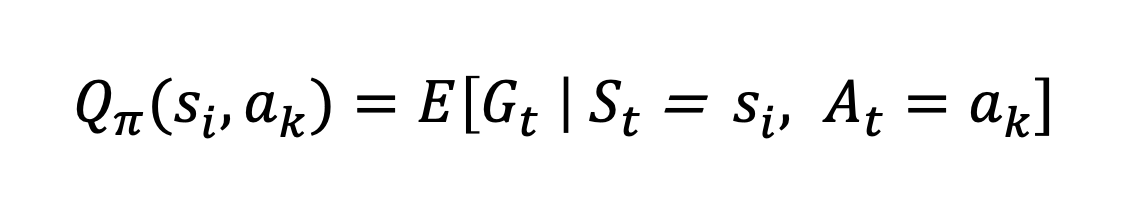
Q는 행동을 고려하여 상태의 가치를 평가하는 함수:
상태 si, 행동 ak일 때의 상태-행동 가치 함수는 상태 si, 행동 ak일 때의 Gt(Return 값 == 누적 보상)와 같으므로,

상태-행동 가치 함수 Q_pi(s, a)는 가능한 모든 상태로부터의 상태 가치 함수들의 기댓값, 즉 정책 pi, 상태 s에서 행동 a를 했을 때 예상되는 장기적인 보상의 기댓값
Bellman Equation
앞서 살펴보았듯 V는 Q로, Q는 V로 표현되었는데 이를 재귀적으로(V는 V로, Q는 Q로) 표현한 방정식


Bellman Optimality Equation
최적 가치: 가장 큰 보상을 받을 수 있는 정책을 따랐을 때의 가치
Dynamic Programming(DP)
- 재귀적인 최적화 문제를 푸는 방법
- MDP를 알아야 가능!!! 상태 전이 확률 P와 보상 함수 R를 정확히 안다는 가정하에서 사용 가능한 기법(현실의 문제에서 적용하기 어려움)
- 정책 반복(Policy Iteration), 가치 반복(Value Iteration)으로 이루어짐
- 정책 반복(Policy Iteration)
- 정책 평가와 정책 개선을 반복 적용해 벨만 방정식을 해결하는 알고리즘
- 정책 평가: 정책 pi가 주어졌을 때 얼마나 좋은지 판단
- 정책 개선: Return의 값이 더 큰 정책으로 업데이트
- 가치 함수의 변화량이 특정한 값 이하가 되거나 반복 횟수를 정해서 반복을 멈추게 할 수 있음
- 정책 평가와 정책 개선을 반복 적용해 벨만 방정식을 해결하는 알고리즘
- 가치 반복(Value Iteration)
- 마지막 과정에서 받은 보상이 뒤로 전달되며 업데이트됨(상태 s'에서 optimal value를 찾은 것으로 상태 s에서의 optimal value를 찾고, ... 반복)
- argmax가 아니라 max 사용 - 한번에 처리 가능, 정책 반복보다 수렴 속도 빠름
- 정책 반복(Policy Iteration)
On-Policy vs Off-Policy
- On-Policy: 행동 결정 정책과 학습하는 정책이 같은 강화학습 - 경험을 많이 쌓아도 정책이 업데이트되면 그 경험을 학습에 사용할 수 없음
- Off-Policy: 행동 결정 정책과 학습하는 정책이 다른 강화학습 - 정책이 업데이트되어도 경험을 학습에 사용할 수 있음(데이터 효율이 좋음)
Exploitation vs Exploration
- Exploitation(이용): 현재 알고 있는 가장 최적의 행동을 선택 - 그러나 모든 행동 중 최적이 아닐 수 있음, 따라서 greedy하게(탐욕적으로) 행동을 선택한다고도 표현
- Exploration(탐험): 경험을 쌓기 위해 아무 행동이나 선택해 봄 - 더 좋은 길이 있어도 exploitation만 하면 그 길을 경험해 볼 기회가 없으니 간혹 탐험을 시도해서 최적의 행동을 찾음
'Aritificial Intelligenece' 카테고리의 다른 글
| [AI] 강화학습 기초 (0) | 2024.07.25 |
|---|